En mars dernier, le baromètre 2024 de l’esprit critique réalisé par OpinionWay, révélait que plus des deux-tiers des Français avaient entendu parler d’intelligence artificielle générative. En tête des outils les plus connus du grand public : ChatGPT.
Un autre sondage réalisé le mois suivant par Viavoice indiquait qu’un français sur deux avait déjà testé le robot conversationnel d’OpenAI, sans même parfois savoir qu’il s’agit d’une IA générative !
Si pour la plupart de nos compatriotes son utilisation reste encore occasionnelle, ChatGPT a néanmoins rencontré un succès fulgurant dès sa sortie. L’outil comptait déjà un million d’utilisateurs cinq jours après sa sortie.
A titre de comparaison il avait fallu respectivement dix mois à Facebook et deux ans à Twitter pour atteindre cette barre fatidique.
 Source Statista
Source Statista Nous avons vu que les origines de l’intelligence artificielle sont anciennes et n’ont pas attendu le joli coup marketing d’OpenAI pour se développer.
On dit d’une intelligence artificielle qu’elle est générative car elle peut créer de nouveaux contenus :
- un texte
- une image
- un son
- une vidéo
Ces contenus, qui n’existaient pas auparavant, ont pu être générés par l’IA sur la base des motifs et structures qu’elle a appris à partir de grandes quantités de données.
Génération d'image et génération de texte
L’IA générative d’image et l’IA textuelle sont des techniques assez différentes. Regardons leur fonctionnement plus en détail.
Comment l'IA parvient à générer une image ?
Click here to display content from YouTube.
Learn more in YouTube’s privacy policy.
Les outils de génération d’images par intelligence artificielle se sont multipliés ces deux dernières années. Dall-E 3, Midjourney, Runway, Adobe Firely, Leonardo, Craiyon, tous rivalisent pour proposer des images de plus en plus qualitatives.
Quels sont leurs principes de base ? Comment l’IA fait-elle pour créer une image de chien ?
La génération d’images par IA fonctionne sur un système en deux parties, appelé encodeur-décodeur.
Reprenons notre exemple précédent. Nous avons compris avec notre exemple du chien comment un réseau neuronal est capable d’identifier la présence de tel objet ou tel animal dans une image.
Il traite cette image par étapes pour en extraire les informations importantes et prendre une décision, sur la base d’un résumé numérique. On dit aussi une « signature ». C’est la première partie.
Pour générer une image de chien, il suffit alors de faire le chemin inverse ! En partant de cette signature, la seconde partie génère une nouvelle image de chien.
L’IA s’entraîne en comparant les images qu’elle crée avec de vraies photos de chiens. Le réseau apprend de façon auto-supervisée à recréer une image et régler ses paramètres.
Deux techniques permettent d’améliorer progressivement la qualité des images générées par IA.
- Les GAN (Generative Adversarial Networks) : Ce système fonctionne avec deux réseaux qui s’améliorent mutuellement. Un « générateur » qui crée des images et un « discriminateur » chargé de distinguer les vraies images des fausses.
Le réseau qui génère les images est entraîné à faire de moins en moins d’erreurs, grâce à un processus appelé rétropropagation. Parallèlement, le discriminateur s’entraîne à repérer les fausses images de plus en plus efficacement. - La diffusion : avec cette méthode, on part d’une image claire sur laquelle on ajoute progressivement des perturbations aléatoires : du bruit. Le réseau est entraîné à supprimer ce bruit pour retrouver une image proche de l’originale. On répète ensuite ce processus avec des images de plus en plus bruitées. On peut alors demander au système de générer une image de chien en partant d’une image très bruitée. Le résultat est une nouvelle image de chien, différente de celles existantes.
Comment l'IA parvient à générer du texte ?
Les IA génératives text-to-text fascinent autant qu’elles peuvent effrayer. Certains établissements de l’enseignement supérieur en ont interdit l’usage, sous peine de sanctions pouvant aller jusqu’à l’exclusion. Elles fonctionnent à partir d’un LLM (Large Language Model), un type d’IA avancé spécialisé dans le traitement du langage naturel.
Même s’il reste le plus connu depuis sa sortie tonitruante fin 2022, ChatGPT n’est pas le seul outil à votre disposition. Gemini, Claude, Le Chat, Grok etc : le choix ne manque pas.
Comment fonctionnent les LLM à la source de ces agents conversationnels ?
Click here to display content from YouTube.
Learn more in YouTube’s privacy policy.
Le traitement automatique du langage (TAL), aussi appelé NLP pour « Natural Language Processing », est un domaine de l’intelligence artificielle qui vise à permettre les interactions homme-machine par le langage naturel. La première étape consiste à convertir les mots en signatures mathématiques appelées des word embeddings. Il s’agit de transformer les mots en vecteurs numériques, une série de chiffres qui capture le sens des mots, leur contexte d’utilisation et leurs relations avec d’autres mots.
On peut visualiser ces mots comme des points sur un graphique : des mots proches en sens sont proches sur le graphique. Des mots comme chien et chienne ont une distance similaire à lion et lionne. Leurs relations sémantiques sont parallèles.
Le système apprend ensuite de manière auto-supervisée. L’IA s’entraîne en devinant des mots manquants dans des textes à trous. Comme elle génère une nouvelle entrée dans un texte, on dit qu’elle est générative. Grâce à un auto-encodeur débruiteur, elle apprend à prédire les mots probables dans un contexte donné. On obtient grâce à ce processus une cartographie des mots et de leurs relations.
Cette représentation est généralement très similaire d’une langue à une autre. Woman et man ont une représentation identique à femme et homme.
Le système devient capable de générer du texte et de répondre indépendamment de la langue. On comprend ainsi pourquoi ces IA deviennent excellentes pour faire de la traduction par exemple.
Revenons à notre agent conversationnel. L’instruction que vous lui donnez en langage naturel s’appelle un prompt.
Votre prompt (phrase ou groupes de phrases) va être découpé en blocs : des mots et même des parties de mots. Ce sont les tokens. Les embeddings, dont nous avons parlé précédemment, sont une représentation vectorielle de ces tokens.
Grâce à un mécanisme d’attention, le système va donc utiliser vos mots, ou plutôt leurs embeddings, pour générer du texte à partir d’une technologie connue sous le nom de transformers.
C’est le T de l’acronyme GPT (Generative Pre-trained Transformer) d’OpenAI, ou de BERT (Bidirectional Encoder Representations from Transformers) de Google.
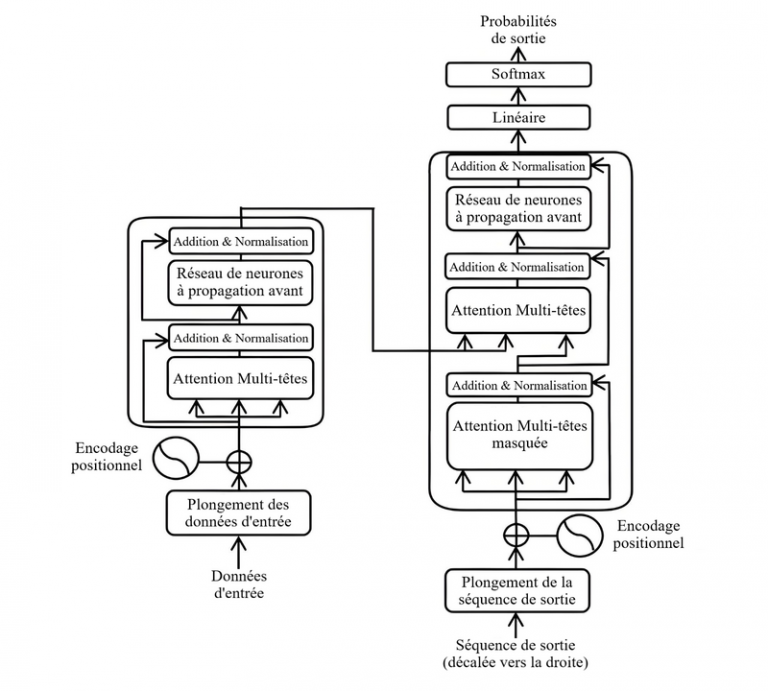
Le pré-entraînement est fait sur la base d’un très large volume de données textuelles. Et après avoir fait des liaisons mathématiques entre les mots, il consiste à lui faire trouver le prochain mot dans un texte. Puis le mot d’après et ainsi de suite.
ChatGPT et plus généralement les LLM sont donc des systèmes entraînés à deviner statistiquement le mot suivant, puis le mot suivant, puis le mot encore après etc… De cette façon, le système génère du texte à la base d’un contexte, fourni par votre prompt !
Les grands modèles de langage (LLM)
Données d'entraînement
Pour apprendre toutes ces fonctions linguistiques complexes, les large language models sont pré-entraînés sur de grands volumes de données. En 2018, GPT-1 a été entraîné sur un corpus de près d’un milliard de mots. BERT sur environ 3 milliards de mots.
Aujourd’hui, les plus grands LLM sont pré-entraînés sur des milliers de milliards de tokens. Les sources principales qui en sont à la base : le bookcorpus et la base des brevets américains, mais aussi les forums, les vidéos et Wikipédia en anglais.

Une fois le pré-entraînement du LLM effectué, on affine ses capacités en l’entraînant sur une tâche spécifique. Cet apprentissage permet de le spécialiser. On appelle cela le fine tuning (ou réglage fin).
On fournit aussi au modèle un système de récompense (le RLHF), puis des règles de sécurité (par exemple, ne pas générer d’insultes etc). Vous l’aurez peut-être remarqué lors de vos interactions avec lui, ChatGPT a été programmé pour être neutre et cordial.
Les applications des LLM
Grâce à leur « compréhension » du langage et leur capacité à générer du texte, les LLM sont donc d’excellents rédacteurs.
Il sont aussi très efficaces pour traduire, résumer un contenu, créer des scénarios, imaginer un quiz ou analyser des sentiments. L’API OpenAI permet même d’intégrer ChatGPT, en tant que chatbot, sur un site ou une application.
Leur capacité à répondre à des questions, à adopter le style de votre auteur préféré, ou à endosser un rôle d’expert sur un sujet peuvent fasciner.
Mais ils peuvent aussi être trompés par des questions mal orientées, donner des réponses erronées ou avoir des hallucinations. Ils sont programmés pour générer du texte, quelle que soit votre demande. On peut donc leur faire confiance, à condition de contrôler leurs réponses.
Et qui mieux que ChatGPT pour vous le confirmer ?

Difficile donc de les assimiler à un moteur de recherche. D’autant que selon les modèles, leur base de connaissance peut avoir quelques mois d’ancienneté.